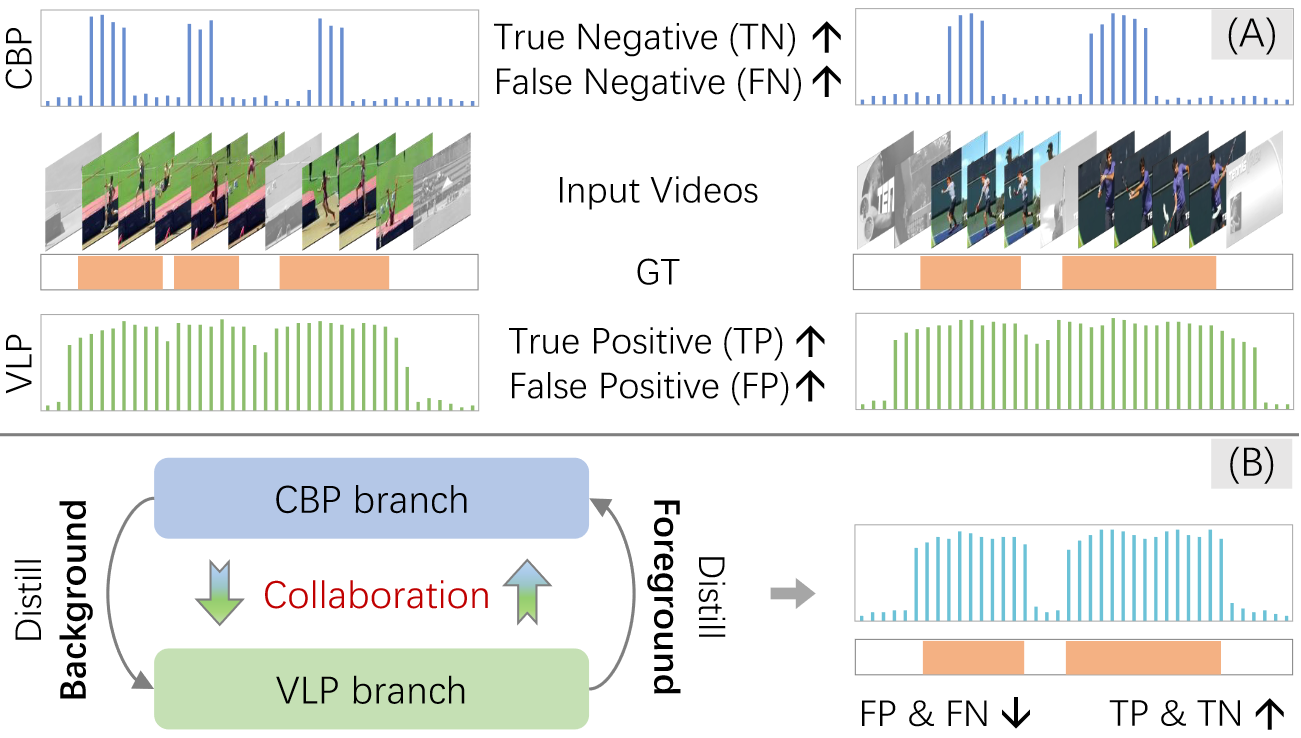
Insight and Motivation: (A) Complementarity. Most works use Classification-Based Pre-training (CBP) for localization, bringing high TN yet serious FN. Vanilla Vision-Language Pre-training (VLP) confuses action and background, bringing high TP yet serious FP. (B) Our distillation-collaboration framework distills foreground from the VLP branch while background from the CBP branch, and promotes mutual collaboration, bringing satisfactory results.
| Weakly-supervised temporal action localization (WTAL) learns to detect and classify action instances with only category labels. Most methods widely adopt the off-the-shelf Classification-Based Pre-training (CBP) to generate video features for action localization. However, the different optimization objectives between classification and localization, make temporally localized results suffer from the serious incomplete issue. To tackle this issue without additional annotations, this paper considers to distill free action knowledge from Vision-Language Pre-training (VLP), as we surprisingly observe that the localization results of vanilla VLP have an over-complete issue, which is just complementary to the CBP results. To fuse such complementarity, we propose a novel distillation-collaboration framework with two branches acting as CBP and VLP respectively. The framework is optimized through a dual-branch alternate training strategy. Specifically, during the B step, we distill confident background pseudo-labels from the CBP branch; while during the F step, confident foreground pseudo-labels are distilled from the VLP branch. As a result, the dual-branch complementarity is effectively fused to promote one strong alliance. Extensive experiments and ablations on THUMOS14 and ActivityNet1.2 reveal that our method significantly outperforms state-of-the-art methods. |
Distillation-Collaboration Framework
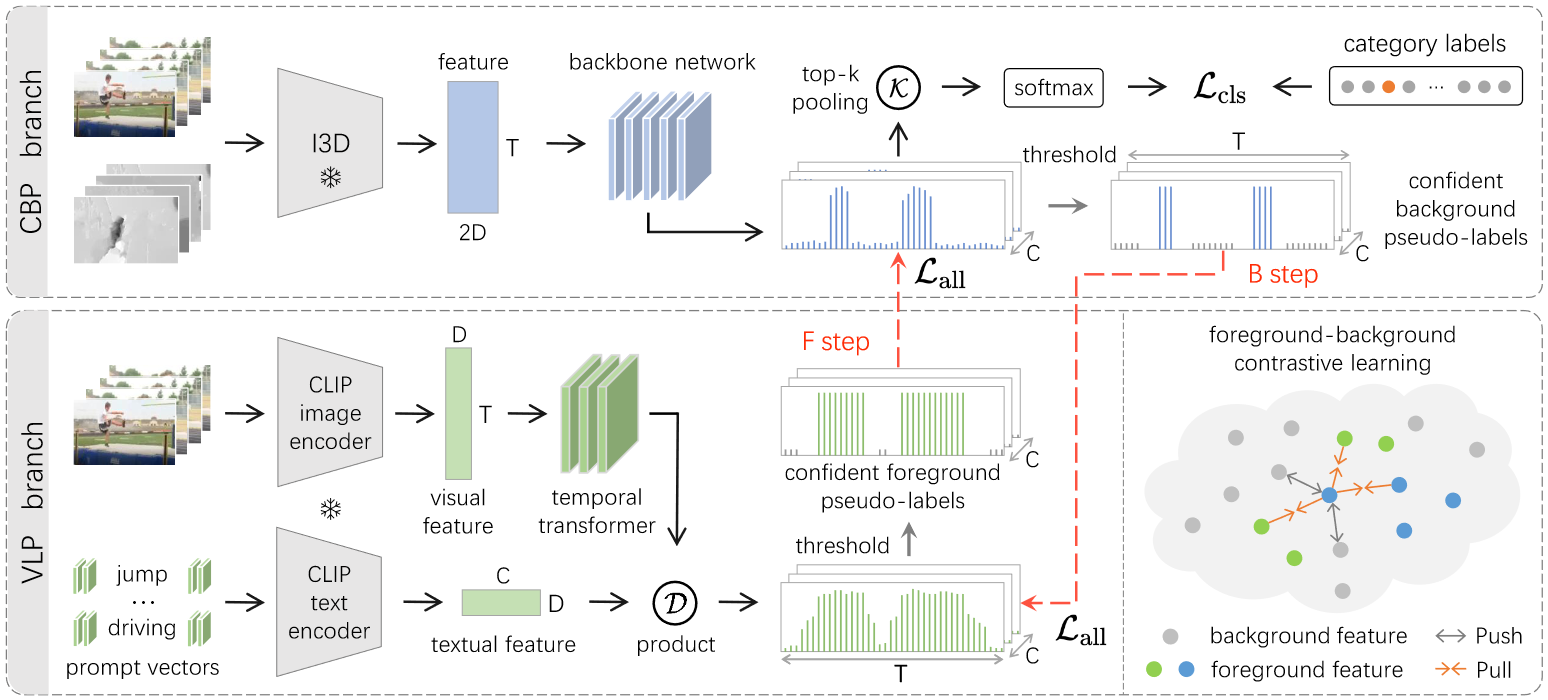
Our framework covers two parallel branches, named CBP and VLP, and is optimized by an alternating strategy. We warm up the CBP branch in advance. In B step, we freeze both CLIP encoders, and distill confident background pseudo-labels from the CBP branch, to train prompt vectors and temporal Transformer in the VLP branch. In F step, confident foreground pseudo-labels are distilled for the CBP branch. We utilize both knowledge distillation loss and contrastive loss during dual-branch collaboration.
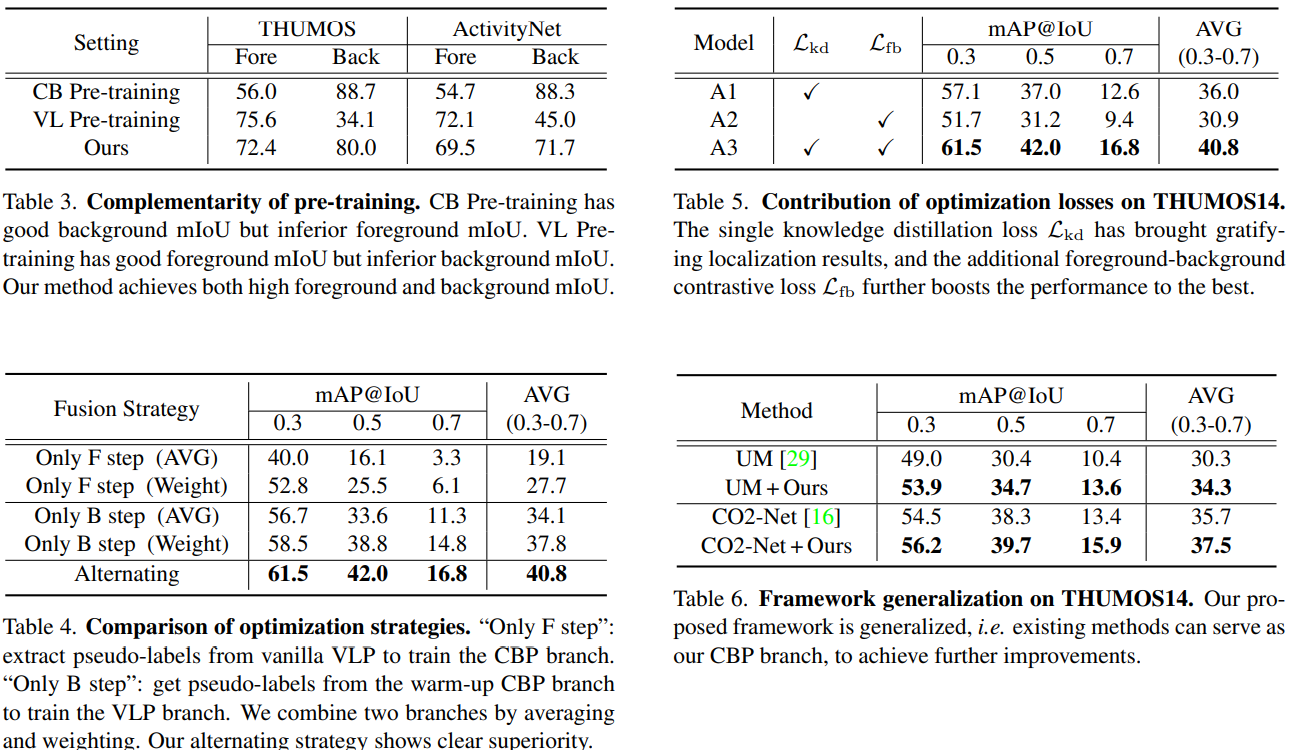
Ablation Studies
Comparisons with SOTA methods
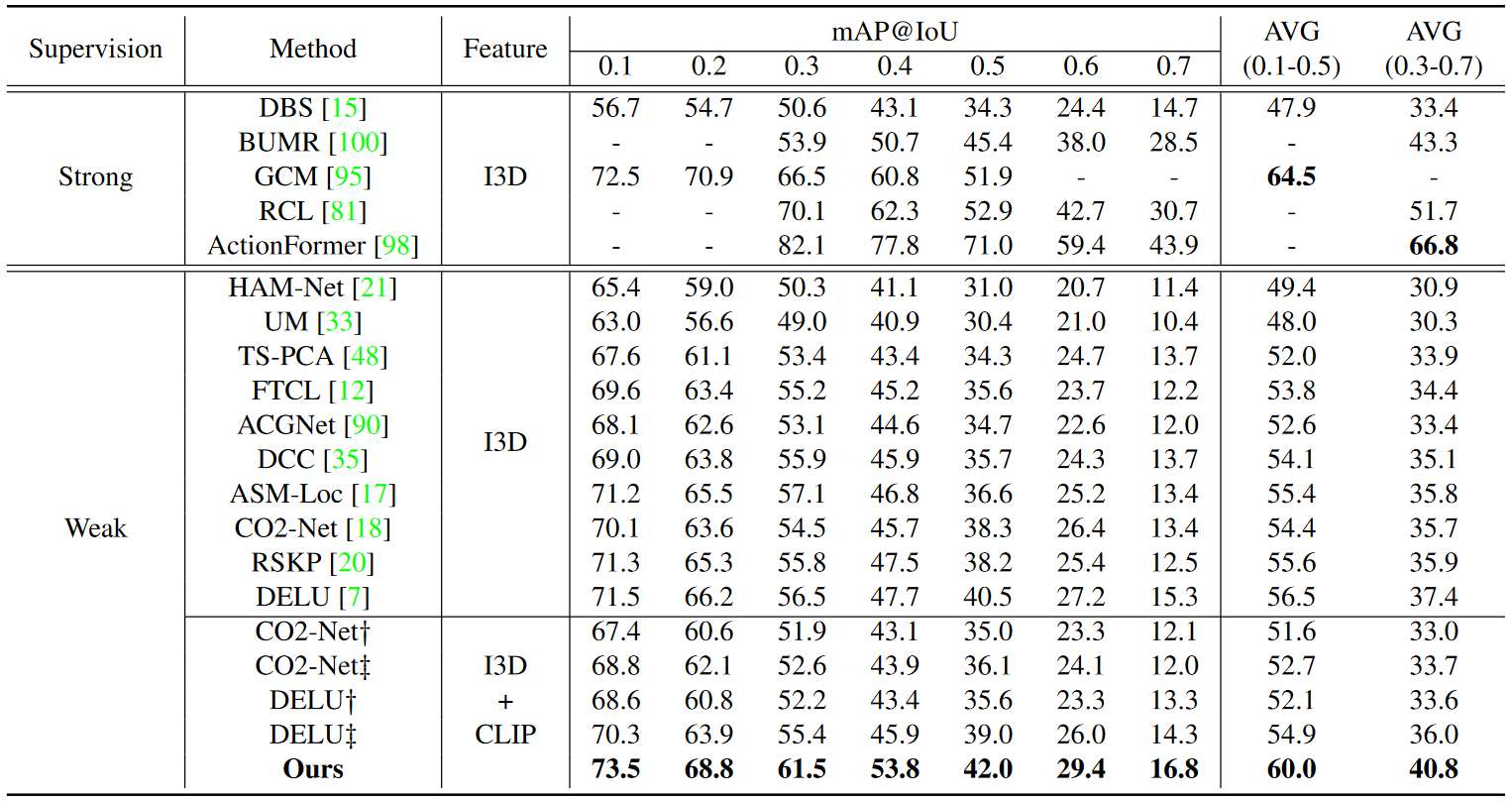
For fair comparisons, we reproduce the results of SOTA methods: CO2-Net and DELU, by inputting both I3D and CLIP features. $\dag$ and $\ddag$ refer to averaging or concatenating these two features. AVG(0.1-0.5) and AVG(0.3-0.7) are the average mAP from IoU 0.1 to 0.5 and from IoU 0.3 to 0.7. Our framework significantly surpasses all weakly-supervised competitors using identical features, and is even comparable to early strongly-supervised methods.
Qualitative Detection Results
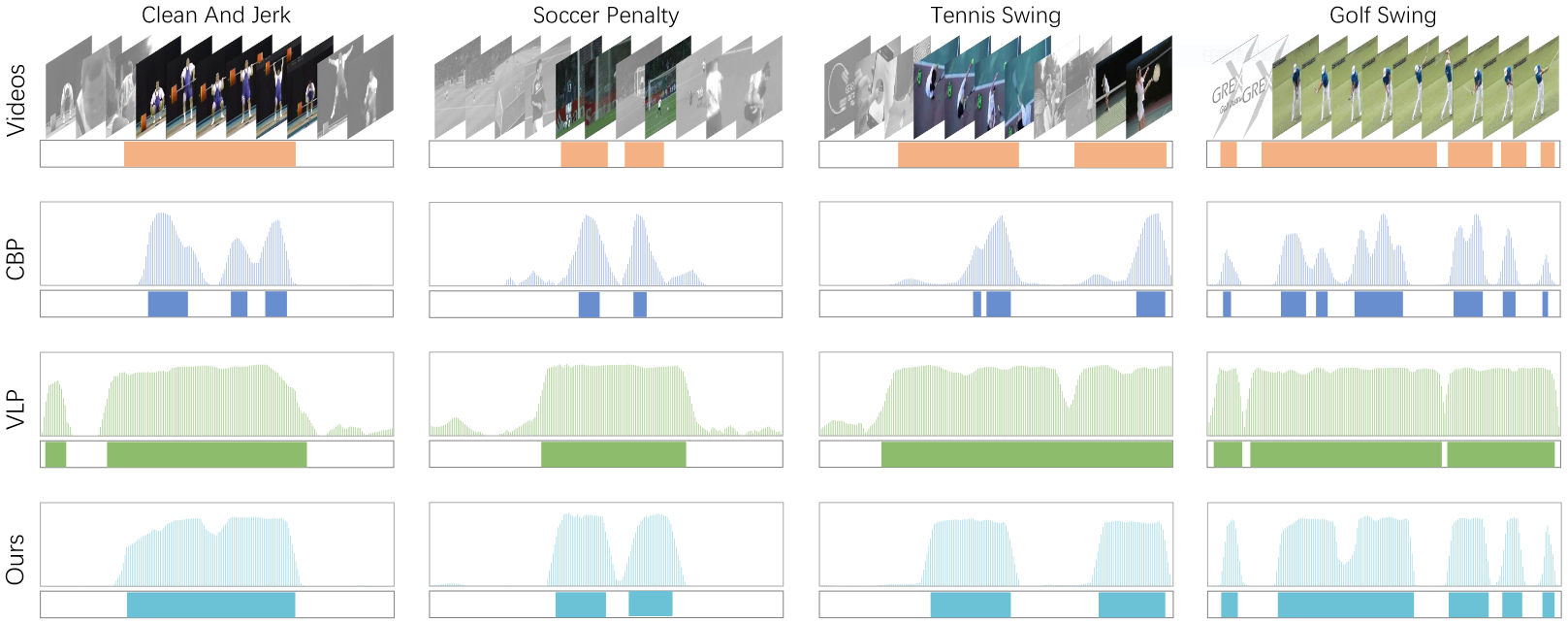
The first two rows are videos and ground-truth action intervals. The last six rows are frame-level action probabilities, and localization results of Classification-Based Pre-training (CBP), Vision-Language Pre-training (VLP), and our framework, respectively. CBP suffers from the incomplete issue, while VLP has the over-complete issue. Our framework distills foreground from VLP and background from CBP, for the strong collaborative alliance, thus bringing more complete and precise results.
Acknowledgements
This research is supported by the National Key R&D Program of China (No. 2022ZD0160702), STCSM (No. 22511106101, No. 18DZ2270700, No. 21DZ1100100), 111 plan (No. BP0719010), and State Key Laboratory of UHD Video and Audio Production and Presentation.